
Processor Companies Weigh Into AI Development With Software Support

Arm, Intel, and NXP are lending their hands to the software world with new hardware-integrated frameworks.
In the competitive world of AI, software tools have become as meaningful as hardware. Companies use frameworks that optimize performance and resource efficiency to bring complex models closer to end devices.
Arm believes the ExecuTorch collaboration may bring many benefits to generative AI applications. Screenshot (modified) used courtesy of Arm
Recently, processor manufacturers have started stepping beyond hardware to enable smoother workflows for developers, creating tool ecosystems that integrate effortlessly with existing systems. In this piece, we’ll look at some of the most notable software developments from the industry’s largest hardware players, including Arm, NXP, and Intel.
Arm’s ExecuTorch Beta Release
Arm recently collaborated with Meta to optimize AI applications on edge devices via the ExecuTorch framework. Built for Arm’s widely-used mobile and IoT processors, this PyTorch-native framework now supports highly compact, quantized models like Meta’s Llama 3.2.
Working with the Arm KleidiAI library, ExecuTorch leverages low-bit matrix multiplication micro-kernels via the XNNPACK backend. Arm claims ExecuTorch can accelerate on-device inference speeds by up to 20% on Arm Cortex-A v9 CPUs. It also employs a four-bit quantization schema that enhances model efficiency by balancing accuracy with lower bit requirements. With this integration, the quantized Llama 3.2 model can achieve over 400 tokens per second during the prefill stage on mobile devices such as the Samsung S24+.
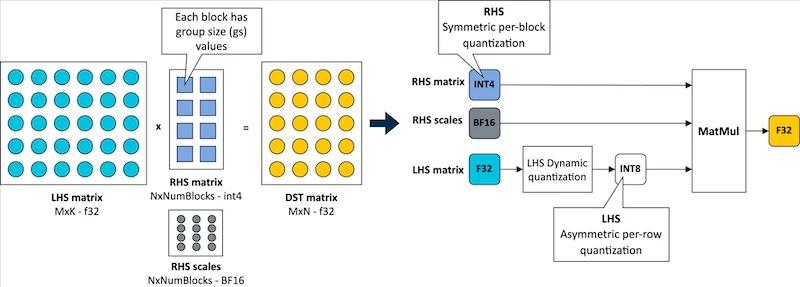
Four-bit quantization with a per-block strategy for weights and per-row quantization for activations. Image used courtesy of Arm
ExecuTorch's architecture enhances model deployment by eliminating the need for model conversion, thus simplifying the developer workflow and improving performance directly on Arm-based devices. This configuration also achieves a twofold improvement in decoding and a fivefold gain in prefill performance. For example, the companies demonstrated a reduced Llama 3.2 model size—1.1 GiB versus 2.3 GiB for traditional BF16 formats—and a 40% lower runtime memory requirement.
NXP’s eIQ Software Expansion
NXP Semiconductors recently launched the eIQ Time Series Studio as part of its enhanced eIQ AI software. This tool introduces an automated machine-learning workflow that expedites model creation and deployment for applications across MCU and application processor platforms. NXP engineered the eIQ Time Series Studio to manage complex time series data from temperature, voltage, and pressure sensors. This allows users to develop models for anomaly detection, classification, and regression. The tool integrates advanced data curation and preprocessing functionalities to optimize raw, sequential data, achieving model precision while balancing memory and storage requirements for resource-constrained devices.
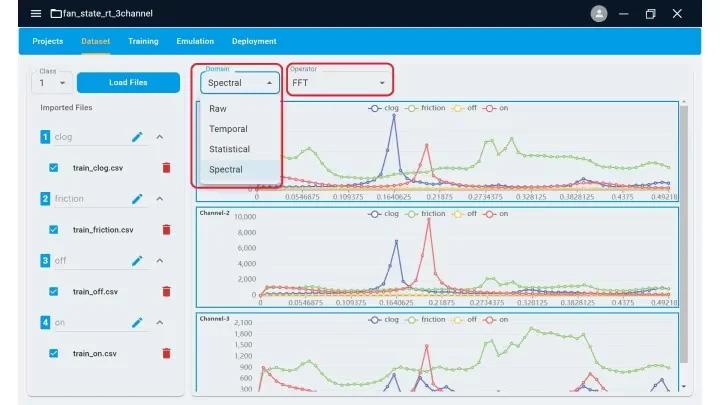
The data input page of eIQ. Image used courtesy of NXP
Moreover, eIQ Time Series Studio provides developers with model auto-generation, optimization, and emulation, transforming traditional iterative workflows into rapid one-click operations. Through the platform’s emulation capabilities, developers can validate model performance in a simulated edge environment, closely mimicking the hardware deployment conditions. Furthermore, the streamlined deployment process, compatible with NXP's MCUXpresso and Code Warrior IDEs, enables direct integration with MCU libraries through simple API calls.
Complementing Time Series Studio, NXP’s GenAI Flow introduces generative AI capabilities with retrieval augmented generation (RAG) fine-tuning, allowing users to tailor LLMs for specific use cases on the edge. Designed for the i.MX applications processor family, this tool secures model customization, training LLMs on domain-specific data without compromising data privacy.
Intel’s PyTorch 2.5 Contributions
Recently, Intel expanded support for Intel GPUs in PyTorch 2.5, particularly the Intel Arc discrete graphics and the Intel Data Center GPU Max Series. The company notably integrated SYCL kernels to extend Aten operator support. This will boost performance in PyTorch’s eager mode, facilitating faster, more efficient model training.
Additionally, Intel refined the torch.compile backend for Intel GPUs, improving inference and training for deep learning workloads. The new PyTorch release upgrades Intel’s data center CPUs' FP16 datatype, which leverages Intel Advanced Matrix Extensions to enhance inference speed and efficiency in both eager mode and TorchInductor.
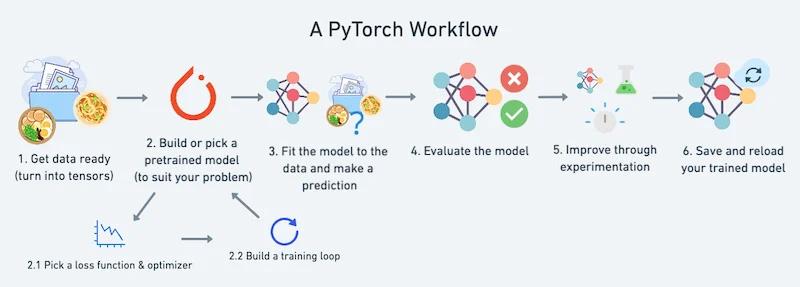
A PyTorch workflow. Image used courtesy of Learn PyTorch
The release also includes the TorchInductor C++ backend for Windows, offering developers a streamlined experience on Windows-based systems.
Hardware-Integrated Frameworks
As AI becomes indispensable across mobile, IoT, and edge platforms, the tools highlighted in this article suggest a shift toward cohesive, hardware-integrated frameworks that simplify model deployment. By aligning software advancements directly with processor architectures, companies like Arm, NXP, and Intel are enabling more efficient and capable AI models within constrained hardware environments. This convergence of hardware and software will likely pave the way for even more powerful edge applications, lower barriers for developers, and accelerate the expansion of AI solutions in diverse sectors.


