
AMD and Untether Take On Nvidia in MLPerf Benchmarks

For the first time, the latest round of MLPerf inference benchmarks includes results for AMD’s flagship MI300X GPU. The challenger showed comparable results to market leader Nvidia’s H100/H200 current generation hardware, though Nvidia won overall—but only by a tight margin.
Nvidia was also challenged by startup Untether, showing its first MLPerf benchmarks in which its SpeedAI accelerator beat various Nvidia chips on power efficiency for ResNet-50 workloads. Google also submitted results for Trillium, its sixth-generation TPU, and Intel showcased its Granite Rapids CPU for the first time.
AMD MI300X
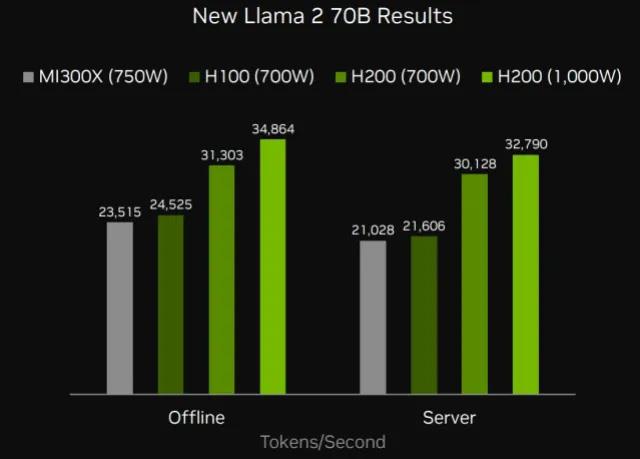
AMD submitted its first results for its Nvidia-challenging data center GPU, the MI300X, showing its performance in single and 8-chip systems for Llama2-70B inference. A single MI300X can inference 2520.27 tokens/s in server mode or 3062.72 tokens/s in offline mode, while 8x MI300Xs can do 21,028.20 tokens/s in server mode and 23,514.80 tokens/s in offline mode. The figures show fairly linear scalability between system sizes. (As a reminder, the offline scenario allows batching to maximize throughput, while the more difficult server scenario simulates real-time queries with latency limits to meet.)
These results are very similar (within 3-4%) of Nvidia’s results for H100-80B on the same workload for 8-chip systems. Compared to Nvidia’s H200-141GB, which is effectively the H100 with more and faster memory, AMD is more like 30-40% behind.
AMD has positioned its 12-chiplet MI300X GPU directly against Nvidia’s H100 and is widely seen as one of the most promising commercial offerings to challenge team green’s hold on the market. MI300X has more HBM capacity and bandwidth than Nvidia’s H100 and H200 (MI300X has 192 GB with 5.2 TB/s versus H200’s 141 GB at 4.8 TB/s), which should be evident in the results for inference of large language models (LLMs). AMD said 192 GB is large enough to hold the whole Llama2-70B model plus the KV cache (an intermediate result) on one chip, avoiding any networking overhead from splitting models across multiple GPUs. MI300X also has slightly more FLOPS than H100/200. Parity with H100 and lagging H200 may leave AMD fans a little disappointed, but these initial scores will no doubt improve in the next round with further software optimizations.
Software-wise, AMD said it made extensive use of its composable kernel (CK) library to write performance critical kernels for things like prefill attention, FP8 decode paged attention and various fused kernels. It also improved its scheduler for faster decode scheduling and better prefill batching.
AMD also previewed its next-gen Epyc Turin CPUs in combination with MI300X; the improvement was fairly marginal at 4.7% in server mode or 2.5% in offline mode versus the same system with a Genoa CPU, but it was enough to push the Turin-based system faster than DGX-H100 by a small amount. AMD Turin CPUs are not on the market yet.

Nvidia Blackwell
Nvidia debuted Blackwell B200 this round. This is the first GPU with the new Blackwell architecture; it has twice as much compute as H100/200 due to being two reticle-sized compute die, and it also has more memory versus H200’s 141 GB at 180 GB. It is also the first Nvidia GPU to support FP4.
A single B200 in server mode can inference 10,755.60 tokens/s for Llama2-70B, up to 4x faster than an H100, or 11,264.40 tokens/s in offline mode, up to 3.7x faster than H100. Note that Nvidia has quantized to FP4 for the first time in these results (submitters can quantise as aggressively as they like, provided they meet a strict accuracy target, which in this case was 99.9%). Versus the H200 (with bigger and faster memory than H100, and quantised to FP8), the difference was more like 2.5× in both scenarios. Nvidia did not say whether it quantized the entire workload to FP4; its transformer engine software enables mixed precision for optimal results during training and inference.
Results for B200 were submitted in the “preview” category, which means Nvidia expects Blackwell to be on the market in six months or less. Because of both companies’ product cadences, AMD’s current generation MI300X will likely come up against Nvidia’s B200 shortly. For Llama2-70B inference, B200 is around 4× faster than MI300X today.
Nvidia and its partners show off results for the new mixture of experts workload, Mixtral-8x7B. This workload has 46.7B total parameters with 12.9 active per token (mixture of experts models assign queries to one of, in this case, eight smaller sub-models, called “experts”). For Mixtral, H200 beat H100 in the same power envelope (700W); H200 has 1.8× more memory with 1.4× more bandwidth but provides around 11-12% more performance.
Nvidia said it is extracting 27% more performance from Hopper GPUs compared to the last inference round, and that much of this work finds its way into its developer tools.
Untether speedAI240
Startup Untether showed off its first MLPerf results, submitting performance and power scores for its second-gen speedAI240 accelerator in several different system configurations. This is a 2-PFLOPS accelerator with more than 1400 RISC-V cores, designed for power efficient AI inference.
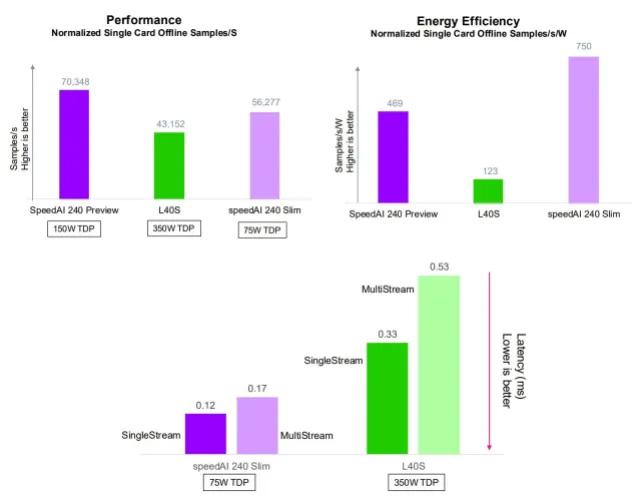
Untether’s 6x “Slim” PCIe cards—which fit into 2U, each with a single accelerator powered at 75 W—can handle 309,752 ResNet-50 inf/sec in server mode, or 334,462 in offline mode. This is around half the performance of an 8x Nvidia H100-SXM-80GB system as submitted by Supermicro, though the Supermicro system is twice as big at 4U and its TDP is more than 10x. Normalizing per accelerator shows one Untether speedAI240 has around 65% the performance of an H100 in this configuration. Remember, Untether does not use HBM—its accelerators use up to 64 GB LPDDR5 memory with bandwidth 100 GB/s.
Untether also has systems in the preview category (meaning they are not on the market yet) based on a bigger single-chip PCIe card that doubles the power available to the accelerator to 150 W. This system also boosts clock frequency slightly. Results improved 35% in server mode or 26% in offline mode on a per-accelerator basis for ResNet-50. Two cards together offer double the performance, demonstrating linear scalability.
Untether’s results really shine in power efficiency. For ResNet-50, 6x accelerators on the slim cards (75 W each) can inference 314 queries per second per watt in server mode, versus 96 for 8x Nvidia H200-141GB—giving Untether around 3× the power efficiency versus Nvidia’s current generation hardware.
In the next round, Untether will look to benchmark its 4-accelerator card, and will take on Bert and bigger LLM workloads next, the company said.
Google Trillium
Google showed results under “preview” for its next-gen TPUv6e, Trillium, which will launch later this year. Trillium can inference StableDiffusion at 4.49 queries/s in server mode or 5.44 samples/s in offline mode. Versus the current-gen TPUv5e in the same round, it roughly triples performance. For comparison, Nvidia GH200 (Grace Hopper 144 GB) can do 2.02 queries/s in server mode and 2.30 samples/s in offline mode—about half of Trillium’s performance.
Google said Trillium is expected to increase peak compute performance 4.7× compared to its previous generation, due to bigger matrix-multiply units and faster clock speed. HBM capacity and bandwidth has also doubled and the bandwidth between chips has doubled too, due to custom optical interconnects.
Trillium also features a new generation of SparseCore, which accelerates embedding-heavy workloads by strategically offloading random and fine-grained access from TensorCores. Unfortunately, Google did not submit results for the DLRM benchmark for either generation of its TPU in this round to show this off.
Intel Granite Rapids
Intel once again showed off its CPUs for AI inference (no submissions from Habana this time). It showed Granite Rapids, its next-gen Xeon server CPU with all performance cores (P-cores, versus efficiency cores or E-cores). Granite Rapids offers 1.9× the performance of previous generation Xeon CPUs—this is an average across all the workloads submitted, which includes only the smaller models, up to and including GPT-J (6B).
The company said it is continuing to invest in AI for its CPU roadmap, including introducing new data types and better efficiency for its AMX (advanced matrix extensions) instruction set extensions.


